Cluster-Robust Regression in Python
This is a short blog post about handling scenarios where one is investigating a correlation across some domain while controlling for an expected correlation across some other domain. If that sentence made no sense to you don't worry, here is a simple example:
You can read much more in-depth about this technique here.
Research Question:
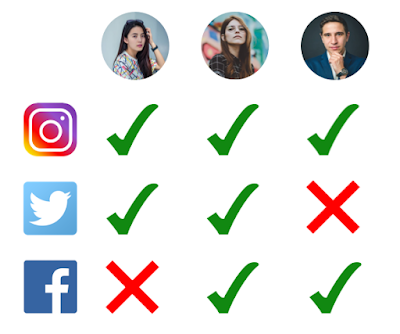
To determine if Instagram users are more likely to also post on Facebook or to Twitter.Analysis Plan:
Perform a t-Test to look at the difference in means of how often Instagram users are posting on Facebook vs. Instagram users posting on Twitter.Problem:
Some users have Facebook accounts (Group A), some users have Twitter accounts (Group B) and some users have both (Group A/B). So we can't really use a Related Samples t-Test or an Independent Samples t-Test. Also, some users post many photos on Instagram and others only make the occasional post. We could therefore expect that the difference between users may be larger than the difference between what we actually want to measure which is Facebook vs. Twitter posting.
Solution:
Cluster-Robust Regression! We will perform a simple regression where standard error is calculated on a "Per-User" basis.You can read much more in-depth about this technique here.
The Simple Method
Clustered Regression is supported and very well documented in Stata using the vce(cluster) argument.
Read about it here: https://www.stata.com/manuals13/xtvce_options.pdf
The (Free) Python Method
After scouring the web and reading countless confusing and poorly documented pages I discovered that the Python StatsModels Library actually does support clustering in its OLS Regression Package, even though it can be extremely difficult to find.
Sample Data
We will use the UCI School Performance Dataset where each line is has information about a specific student and their grades in a course. This dataset is relevant because the students came from 2 different schools, so it is reasonable to suspect that performance may be similar within the 2 schools. We will see if the number of absences is correlated with final-grade mark and cluster based on "school attended"
Writing Code
Lets begin by loading in the dataset and printing the first few lines:
Next lets isolate our dependent and independent variables and run a "normal" un-clustered regression:
Output:


Output:

A coefficient of 0.0196 and a p-value of 0.497 indicates no significant correlation
Lets now perform the robust regression with clustering on "school" to control for the similarities within schools.
Output:

A coefficient of 0.0196 and a p-value of 0.143 indicates no significant correlation
Still, there is no significant correlation, however; there was a notable change in p-value.
Further Reading
I would highly recommend anyone who is interested in this type of modelling to read A Practitioner’s Guide to Cluster-Robust Inference as it goes into much more detail on the statistics behind the code and gives a thorough explanation of performing clustered regression in Stata.
Source Code
Full project repository available here
Thanks for one marvelous posting! I enjoyed reading it; you are a great author. I will make sure to bookmark your blog and may come back someday. I want to encourage that you continue your great posts, have a nice weekend!
ReplyDeleteOnline training in USA
Nice post. Thanks for share.
ReplyDeletedata analysis training course london
if you wanna get new latest features then click here...
ReplyDeleteStata Crack
CPUID HWMonitor Crack
Resharper Crack
HitPaw Screen Recorder Crack
Evernote Crack
Studio 3T Crack
Resharper Crack
IDM Crack
ReplyDeleteExcellent post, Its really friendly article...
Coolutils Total PDF Converter Crack
4K Video Downloader Crack
Stata Crack
IVT BlueSoleil Crack
VMWare Workstation Pro Crack