Cluster-Robust Regression in Python
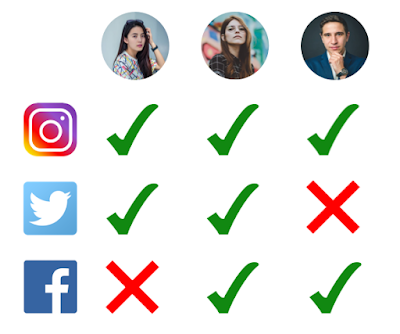
This is a short blog post about handling scenarios where one is investigating a correlation across some domain while controlling for an expected correlation across some other domain. If that sentence made no sense to you don't worry, here is a simple example: Research Question: To determine if Instagram users are more likely to also post on Facebook or to Twitter. Analysis Plan: Perform a t-Test to look at the difference in means of how often Instagram users are posting on Facebook vs. Instagram users posting on Twitter. Problem: Some users have Facebook accounts (Group A), some users have Twitter accounts (Group B) and some users have both (Group A/B). So we can't really use a Related Samples t-Test or an Independent Samples t-Test. Also, some users post many photos on Instagram and others only make the occasional post. We could therefore expect that the difference between users may be larger than the difference between what we actually want to measure which is Facebo...